
¿Puedo comprar tu caché KV?
Descubre cómo precomputar el caché KV de documentos reduce costos de inferencia en IA hasta 50x. Una propuesta simple y efectiva para agentes.
Descubre cómo precomputar el caché KV de documentos reduce costos de inferencia en IA hasta 50x. Una propuesta simple y efectiva para agentes.

¿Quieres ejecutar modelos de lenguaje como 70B en tu PC con solo 8GB de VRAM? Descubre técnicas de cuantización y optimización en esta guía práctica.

El nuevo método SFF (Smoothed Full Fine-tuning) suaviza el paisaje de pérdida no convexo para optimizar el ajuste fino de grandes modelos de series temporales. ¡Descubre sus beneficios!
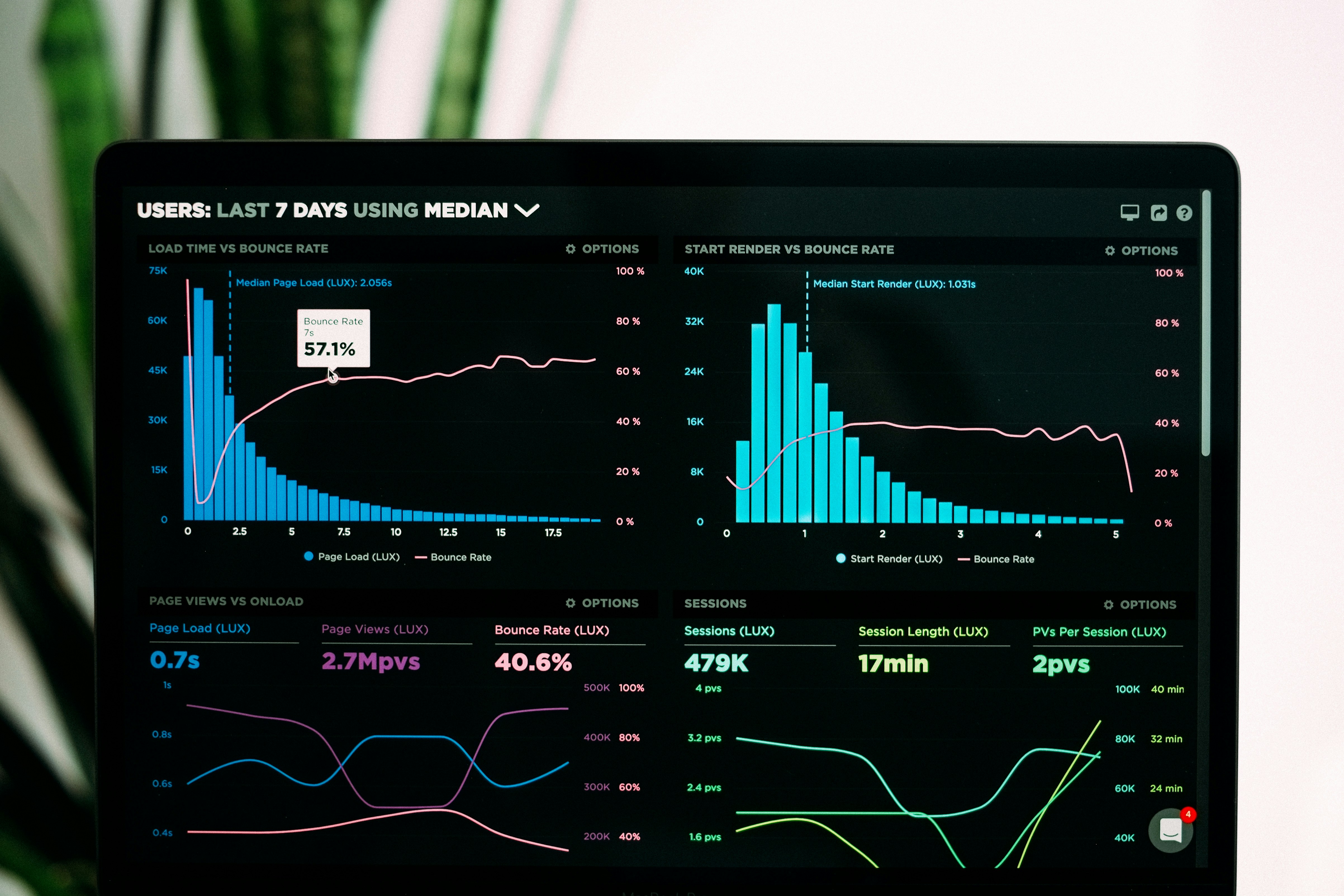
Los modelos grandes de IA transforman el análisis de series temporales y datos espacio-temporales. Encuesta completa con perspectivas y recursos.

Entrena un MoE de 120B en una sola máquina con 8 GPUs usando reversibilidad y escalado preservador de estado. Eficiencia sin precedentes.

Mejora la precisión de modelos pequeños hasta un 6.2% usando guía de modelos grandes sin entrenamiento. Descubre Speculative Thinking.

El pensamiento especulativo guía modelos pequeños con modelos grandes, mejorando precisión un 6.2% y reduciendo salida un 15.7%.

QUIVER incorpora vistas cuántico-informadas para mejorar representaciones en grandes modelos de ML, ofreciendo mejoras medibles en QM9 y JetClass.

Optimiza el ajuste fino de modelos grandes con adaptadores Kronecker. Conoce CDKA, una nueva técnica que mejora la capacidad y eficiencia mediante el diseño estratégico de componentes.

FlexRank extrae submodelos de capacidad variable de modelos sin reentrenar. Optimiza costos y rendimiento para despliegue adaptativo a todo presupuesto.

Descubre CRAFT, un marco que replica expertos con granularidad fina para mejorar el rendimiento de modelos MoE hasta un 20% sin modificar el modelo.

Por primera vez, se demuestran cotas de generalización no triviales para redes profundas sin modificaciones, incluso con 600M parámetros. Análisis basado en la geometría de los datos.
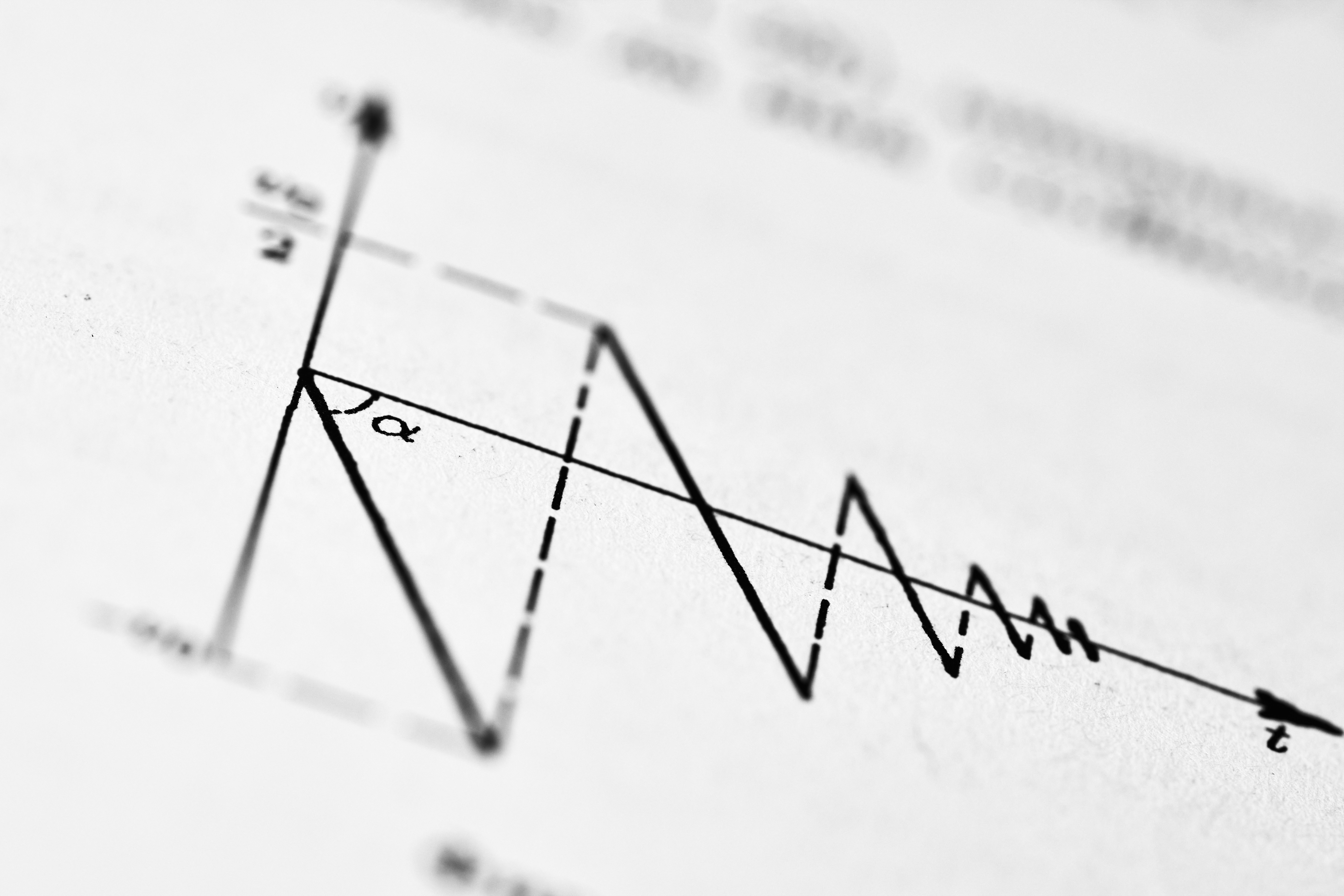
Descubre RefLoRA, una nueva técnica de fine-tuning que acelera la convergencia y mejora el rendimiento de modelos grandes con mínimo costo computacional.

Descubre LiMuon, el optimizador ligero y rápido que reduce memoria y complejidad muestral para entrenar modelos grandes. ¡Mejor rendimiento!

Descubre cómo el alcance espectral mide la capacidad de los modelos grandes para explotar señales débiles en la cola espectral, reduciendo la pérdida mediante el aprendizaje de características.